

Each Android version update comes with a boatload of changes, some more than others. The ratio of user-facing features to developer APIs in each new version varies tremendously, but most changes are actually invisible to users. Performance improvements are particularly hard to notice, even if they can be quantified.
Like every new Android release, Android 13 has a couple of performance-related optimizations here and there, but one of the most impactful improvements may be coming from an update to the underlying Linux kernel. Linux’s new multi-generational LRU framework, developed by Google, stands to vastly improve the kernel’s page reclaim strategy, yielding substantial improvements to memory management and CPU use. In this week’s edition of Android Dessert Bites, I’ll explain how Linux’s memory management is getting better with multi-gen LRU, and how this trickles down to better performance for Android devices.
How Linux views memory
Before I talk about multi-generational LRU, I first need to explain the basics of how Linux manages memory, and I mean the basics. Linux’s memory management subsystem is extremely complex, so explaining every term and parameter would take forever. You only need to know a few concepts to understand how multi-gen LRU improves things, fortunately.
First of all, we need to talk about the difference between real memory and virtual memory. Real memory refers to the actual, physical memory (RAM) that’s in the device. The total amount of real memory is finite, so a phone advertised as having 4GB of RAM has 4 gigabytes of real memory to work with. The location of each byte of data (4GB means 4294967296 or 232 bytes) is referenced by an address, the total number of which is called the address space (for a 4GB RAM system, the addresses would range from 0 to 232 -1).
When you launch an app on your phone, its code is loaded into memory as a process, as are any files they’re accessing. If apps were given free reign to reserve an explicit range of memory addresses for their execution, then we’d quickly run into memory allocation problems. This is because apps would overallocate memory for fear of not having enough. That’s just one of the many problems with letting apps specify the memory addresses they’ll use, and it’s partly why most modern systems implement virtual memory.
With virtual memory, the system handles memory management. Apps instead reference virtual memory locations using a virtual memory address, and the system handles the mapping between virtual addresses and the actual location they point to in real memory. This way, apps don’t have to worry about where their data is actually being stored in real memory.
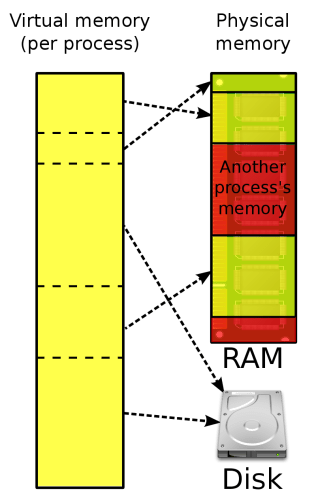
An added benefit of this abstraction is that a portion of the storage device can be reserved for use as virtual memory (called the swap space). The total amount of virtual memory that’s usable is thus comprised of the real memory plus the swap space. Swap space doesn’t perform identically to real memory, though, because the read and write speeds of physical RAM are much higher than most storage devices. Still, it’s useful to have because the system’s out of memory (OOM) killer won’t kick in to kill processes to free up memory if there’s available swap space to use.
Regardless of how much virtual memory is available, though, the system doesn’t keep a 1:1 byte mapping between virtual memory and real memory. Instead, the virtual address space of a process is mapped to real memory in chunks of bytes called pages, which are typically 4KB in size. The page table contains the mapping between the virtual address of each page (called the page table entry [PTE]) and the location of its corresponding chunk of real memory, called a frame. The page table itself is stored in a chunk of memory that’s only accessible by the system.
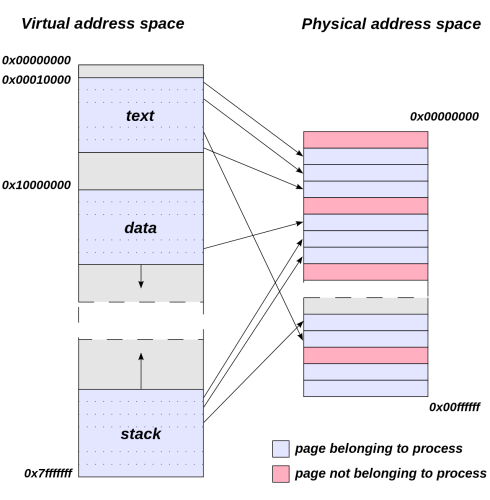
Pages are necessary because they allow for the address space of a process to be noncontiguous, as the system can just move other processes’ pages around when a process needs more memory. Eventually, though, some of those pages will need to be freed up for use by other processes. When this happens, the system will need to evict pages claimed by other processes.
It wouldn’t be good if the system just evicted pages arbitrarily, though, because they may hold some valuable or unsaved data. Instead, an algorithm decides which pages to evict and when they should be evicted. That algorithm is based on a least recently used (LRU) principle, which generally evicts the pages that haven’t been accessed very much recently (hence the name). It’s this algorithm that multi-generational LRU improves upon — the “multi-generational” bit in the name will make sense once in a bit.
How Linux currently manages pages
Linux keeps track of pages using two pairs of lists; one pair tracks file-backed pages while the other tracks anonymous pages. File-backed pages hold data that originate from some file in storage in contrast to anonymous pages which do not. The reason these two types of pages are tracked independently is because there’s a difference in how they’re evicted. While file-backed pages can just be written back to storage, anonymous pages must be written to swap space. Swap space, as I mentioned before, is much slower than physical RAM, so the kernel is biased towards evicting file-backed pages instead.
Within each pair is an active list and an inactive list. Pages that have just been accessed at put at the top of the “active” list followed by other recently accessed pages. Pages that haven’t been recently accessed are moved from the “active” list to the “inactive” list, but they can be moved back if a process accesses them.
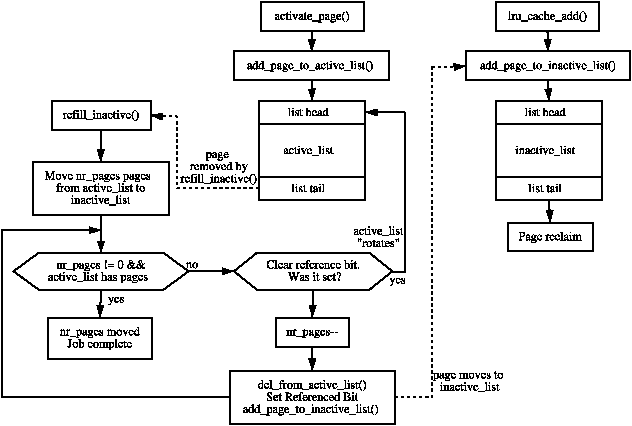
Predicting which pages will be accessed in the near future is difficult, so it makes sense that the kernel considers least recently used pages for eviction. However, Google engineer Yu Zhao identified a few problems with the current page reclaim approach, namely that it’s “too expensive in terms of CPU usage and it often makes poor choices about what to evict.” To be more specific, the current approach:
- Often puts pages in the wrong list because the sorting is too coarse.
- May evict useful file-backed pages even when there are idle anonymous pages in memory.
- Scans for anonymous pages and gets their associated PTEs using a costly reverse mapping algorithm.
#1 and #2 both result in unwanted (from the user’s point of view) page evictions, while #3 results in higher CPU usage if there are a lot of pages to scan.
To solve these problems, Google proposed the multi-generational LRU framework, which expands the number of LRU lists to make page reclaim more accurate and changes how page scanning is done to reduce CPU usage.
How Linux will manage pages with multi-generational LRU
Instead of having just two LRU lists in each pair representing “active” and “inactive” pages, multi-generational LRU introduces lists inbetween called generations. Just-accessed pages are placed in the youngest generation, while pages that haven’t been accessed recently are moved to the next older generation. Like before, any page that has been accessed recently is moved back to the youngest generation, while idle pages are moved to older and older generations the longer they’re unused. When the kernel needs to evict pages, it only needs to look at the pages in the oldest generation. The number of generations can be configured based on the device; phones might only have four, while servers might have many more. This multi-generational approach should thus be more accurate than the current two-list approach, as it’s more likely that a page that has been moved to the oldest generation is actually unneeded compared to a page that was moved from the active to inactive list.
Generations can be further subdivided into tiers, which sort pages based on the frequency of accesses via file descriptors. A file descriptor is basically an index that identifies an open file. The reason this is tracked is because it’s something that can be easily tracked — there’s “no way to track how many times a page has been accessed via page tables mapping it,” according to Zhao. Pages that are only accessed once are the best choice to evict, so a page that’s accessed more frequently than others should be placed in a higher tier.
Like with the current approach, multi-generational LRU is also biased towards evicting file-backed pages. The oldest generation of file-backed pages may be evicted ahead of the oldest generation of anonymous pages. On the other hand, multi-generational LRU also makes it easier to find and evict idle anonymous pages by allowing for the ready comparison of the ages of anonymous and file-backed pages.
The current approach scans for anonymous pages and then uses reverse mapping to find their associated PTEs, which contains a bit that signifies whether that page was recently accessed. In contrast, the multi-generational LRU framework scans the page table directly, avoiding costly reverse lookups entirely.
According to Google’s fleetwide profiling, multi-generational LRU yields an “overall 40% decrease in kswapd [the kernel daemon that manages virtual memory] CPU usage,” an “85% decrease in the number of low-memory kills at the 75th percentile,” and an “18% decrease in app launch time[s] at the 50th percentile.” Those are impressive metrics that show just how much multi-generational LRU impacts memory management and CPU overhead, so it’s no surprise to see that Google has already begun rolling out the framework to millions of users in addition to pushing for its adoption into the upstream Linux kernel (in line with their “upstream first” approach).
In fact, Google has already rolled out multi-generational LRU to “tens of millions of Chrome OS users” and “about a million Android users”, though it’s worth noting that those “Android users” were actually running Android on Chrome OS through ARCVM. The feature is headed to other Android devices with a newer version of the Linux kernel, however. Google has backported the patch set to the android13-5.10 and android13-5.15 branches of the Android Common Kernel. Kernel developers have to compile the kernel with CONFIG_LRU_GEN enabled, then run
echo y > /sys/kernel/mm/lru_gen/enabled
to enable multi-generational LRU. This sysfs control will be hooked up to a device_config property, making it even easier to enable multi-generational LRU if the kernel was built with it.
Currently, there aren’t any Android smartphones out there with multi-generational LRU support enabled, but we won’t have to wait too long for the feature to make its way into devices. Google will probably begin experimenting with it soon on the Pixel 6 series, for one. New flagship phones launching with Android 13 out of the box will probably come with support for it given that current flagships already ship with kernel version 5.10. Phones upgrading to Android 13 probably won’t get this feature, though, since kernel version requirements have been frozen under the Google Requirements Freeze (GRF) program. Custom kernel developers, on the other hand, can enable the feature on current devices by rebasing their work on top of the latest GKI; some may even choose to backport it to unsupported kernel versions.
While I’m excited by the performance improvements that multi-generational LRU will bring to Android 13 devices, I’m not sure if this is an improvement that’ll actually be noticeable in day-to-day use. Google came up with aggregate numbers by profiling a fleet of devices in the millions, so there’s bound to be devices that were impacted less than others. Devices with less RAM and slower CPUs will probably feel these improvements the most, but flagships with 12GB or more of RAM and the best processors may not. I’ll have to wait for Google to roll out Android 13 onto my own Pixel 6 Pro to see if this (and other under-the-hood performance improvements) will actually be noticeable, assuming the Pixel 6 Pro actually gets the feature, of course.
Thanks for reading this week’s edition of Android Dessert Bites, and special thanks to developer Luca Stefani for sharing the news about multi-generational LRU’s inclusion in the ACK. While writing this article, I simplified a lot of things so I could explain multi-generational LRU without getting bogged down in details. There’s a lot of technical details that I left out. If you’re interested in learning more, I highly recommend reading these two articles by Jonathan Corbet for LWN: [1] [2]. Once you’re done with that, check out the official design doc and admin guide.



{kind=link}
{kind=link}